
Abstract
Cocoa growing is one of the main activities in humid West Africa, which is mainly grown in pure stands. It is the main driver of deforestation and encroachment in protected areas. Cocoa agroforestry systems which have been promoted to mitigate deforestation, needs to be accurately delineated to support a valid monitoring system. Therefore, the aim of this research is to model the spatial distribution of uncertainties in the classification cocoa agroforestry. The study was carried out in Côte d’Ivoire, close to the Taï National Park. The analysis followed three steps (i) image classification based on texture parameters and vegetation indices from Sentinel-1 and -2 data respectively, to train a random forest algorithm. A classified map with the associated probability maps was generated. (ii) Shannon entropy was calculated from the probability maps, to get the error maps at different thresholds (0.2, 0.3, 0.4 and 0.5). Then, (iii) the generated error maps were analysed using a Geographically Weighted Regression model to check for spatial autocorrelation. From the results, a producer accuracy (0.88) and a user’s accuracy (0.91) were obtained. A small threshold value overestimates the classification error, while a larger threshold will underestimate it. The optimal value was found to be between 0.3 and 0.4. There was no evidence of spatial autocorrelation except for a smaller threshold (0.2). The approach differentiated cocoa from other landcover and detected encroachment in forest. Even though some information was lost in the process, the method is effective for mapping cocoa plantations in Côte d’Ivoire.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
The Cocoa tree (Theobroma cocoa) is a major cash crop in the forest region of West Africa. It is grown for cocoa beans which are known to be used as input in the agro-industrial sector (chocolate and beverage production), but also in cosmetic and pharmaceutical products. Cocoa beans and cocoa food preparations are the first exported commodities of the region. They represent about 5% of the revenues from exports, more than precious stones (3%) and their primary destinations are the Americas (40%), Europe (28%), and Asia (16%) (ECOWAS 2016). At a microeconomic level, cocoa farming is the basis of the livelihood of about two million farmers in the West African cocoa belt (Boeckx et al. 2020). Despite the fact that revenues from cocoa stricto sensu are not sufficient to reach descent living income (only 33% of farmers in Ghana has a sufficient income from cocoa Boeckx et al. 2020), and the burning question of child labour in the cocoa value chain (Busquet et al. 2021; ILO 2017; International Anti-slavery 2004), the sustainable intensification of cocoa production could be a solution to poverty alleviation (Boeckx et al. 2020). The demand for cocoa will increase since the global cocoa beans market size is projected to expand by 7.3% in 2025, mainly due to the rapid growing of chocolate industries in emerging economies such as China and India (GVR 2019).
Côte d’Ivoire is the world largest producer of cocoa beans producer, with over 2 million tons in 2020, which makes up for approximately 39% of the world’s cocoa production (Shahbandeh 2021). For that performance, 47 000 ha of forest were cleared in 2020 (Mighty Earth 2021). Smallholder farmers take advantage of soil fertility and land availability to establish new cocoa farms at the expense of forest (Ruf et al. 2014). Encroachments in protected areas where reported, with alarming consequences such as habitat degradation and loss of wildlife -especially for primate species-, carbon emissions and soil degradation (Abu et al. 2021; Dean 2019; Bitty et al. 2015). Cocoa farming is the main driver of deforestation, responsible of the loss of more than 80% of the forest cover in Côte d’Ivoire between 1961 and 2000 (Sabas et al. 2020). Here the term cocoa and cocoa plantation will be used alike to refer to cocoa farming.
Certification of cocoa, which includes environmental standards, was introduced to limit deforestation. These standards include sustainable farming and reduced deforestation, mainly to ensure that cocoa farms are established outside protected area (ProLand 2020). Since its introduction in Côte d’Ivoire in 2005, certification has not consistently prevented deforestation. One reason is that it is voluntary, but the main reason is the gap in the geographic coverage. Weakness in traceability was reported as the most critical factors due to a lack of accurate maps of cocoa, which results in poor auditing and difficulty for the enforcement of standards (ProLand 2020). Efforts have been made to limit cocoa extension, by improving old cocoa farm productivity through the introduction of forest trees in cocoa plantations; but also by advancement of surveillance around the Comoé and Taï National parks. (GIZ 2020; Pye-Smith et al. 2016). However, these efforts have not been geographically evaluated due to the lack of a robust method to generate accurate maps.
Freely-available remote sensing imagery from the Sentinel mission, provided by the European Space Agency (ESA) has been used for the detection and mapping of cocoa plantations in West Africa. Abu et al. (2021) detected cocoa and its impact on protected areas in Côte d’Ivoire. With the same dataset processed with deep learning, it was possible to separate full sun cocoa and cocoa agroforestry (cocoa associated with forest trees) in the same region (Ashiagbor et al. 2020). However, cocoa farms are difficult to map, especially in the regions where they share the landscape with other spectrally overlapping crops such as rubber and palm oil. This create a heterogenous landscape also referred to as complex landscape where the classified map will have a disproportionate number of misclassified pixels (Fillela 2018). To ensure image classification of good quality and with high resolution imagery could be used in combination with open-source data. This solution was used to successfully delineate cocoa agroforests in Cameroon, and to classify different agroforestry systems (AFS) in Mali (Aguilar et al. 2018; Numbisi et al. 2019). Such high-quality map comes at a cost in terms of the price, geographic restriction, and the difficulty to integrate it in a near-real time monitoring system.
Another solution is to use freely available imagery for the classification of cocoa farms while presenting a spatial assessment of the classification error alongside the classification. It is acknowledged that the confusion matrix is not informative enough to evaluate a classification, since it does not provide any spatial information on the error. Therefore, we introduced a spatial error assessment workflow as a supplement for the evaluation of a classified map (Comber et al. 2020; Narayan et al. 2021; Roodposhti et al. 2019). The spatial evaluation of the classification is a post classification method that is used to identify pixels with a high probability of being misclassified. It is based on the analysis of the heterogeneity at each pixel based on the prediction probabilities (Roodposhti et al. 2019). It also evaluates the spatial correlation of the error to identify local conditions that affect the classfication (Comber et al. 2020). The application of this classification workflow is still missing in West Africa. Therefore, the aim of this study is to model the spatial distribution of error on the classified map to provide reliable cocoa maps in Côte d’Ivoire. The study neither assesses the performance of classification techniques nor evaluates the type of input data, as it rather aims at detecting and mapping misclassified pixels. The hypotheses are: (i) the analysis of the heterogeneity of each pixel could reveal misclassified pixels; and (ii) spatial error assessment could reduce false detection of cocoa encroachment from non-protected into protected area; (iii) the distribution of the classification error is spatially correlated and could be explained by satellite derived indices.
Methods
Study area
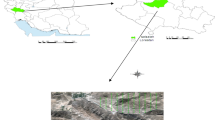
The study was conducted in the southern part of Côte d’Ivoire. The area was a forest region associated with the transitional equatorial climate. Agriculture was the main activity to support the economic life in the region. Within the region, available lands are promptly converted into plantations of cash crops such as cocoa (Theobroma cocoa), rubber (Hevea brasiliensis) and oil palm (Elaeis guineensis), but also for food crops like yam (Dioscorea alata), rice (Oriza sativa), and cassava (Manihot esculenta). Agricultural plantations are located next to two protected forests in the study area, including the northern part of Taï National Park and a portion of the wildlife reserve of N’Zo. These are fully protected areas, with no human intervention.
A field campaign was conducted in March 2020, in the administrative subdivisions of Gueyo and Buyo (Fig. 1). The data acquisition consisted of collecting georeferenced points and polygons in AFS, using sampling plots of 25 × 25 m, which were used in the image classification workflow. Four AFS were considered: (i) cocoa plantations (full sun cocoa or cocoa agroforestry) with at least two production cycles; (ii) Rubber and (iii) oil palm plantations as monoculture planted in rows, often established on formal agricultural plots; and (iv) agricultural farms dedicated to food production including cotton (Gossypium sp). In total, 139 referenced polygons were collected: 30 plots of cocoa, 31 plots of rubber, 16 plots of palm and 62 agricultural farms.

Study area in Southern Côte d’Ivoire. Land cover mask represents the area corresponding to water forest, and urban areas. Gueyo and Buyo are the administrative subdivisions where the field work was carried out
Overview of methodology
The data processing was organized in three steps: (1) supervised image classification from which two outputs were generated: a classification map and the probability maps of each class. (2) the Shannon entropy at pixel level was calculated using the probability maps, and different thresholds were specified to model the spatial distribution of the classification error (Roodposhti et al. 2019). (3) A geographically weighted regression was used to evaluate the spatial autocorrelation of the classification error (Comber et al. 2020).
Data pre-processing
Sentinel-1
The Sentinel-1 (S1) C-band Synthetic Aperture Radar data provided by the ESA was used in combination with optical data to deal with clouds in the region of interest. The selected acquisition mode was the Interferometric Wide swath (IW) with VV and VH polarisations, which is the main acquisition mode over land and satisfies most current service requirements such as preserving revisit performance (Copernicus 2022). With Google Earth Engine (GEE), a composite image (median pixel value) was created between 2017 and 2020, which is corresponding to the period of exponential expansion of cash crops in the area (Yao et al. 2020). The median image was used to be able to combine S1 with Sentinel-2 (S2). A mosaic image of the study area was finally downloaded at the spatial resolution of 10 m.
The texture information was retrieved from the VV and VH bands using the Grey Level Co-occurrence Matrix (GLCM) (Table 1). Texture parameters from GLCM provide valuable information on the spatial relationship between pixels on the image, and also significantly improve the classification accuracy, especially for heterogenous landscapes with open canopy like cocoa plantations (Mishra et al. 2019). To generate the GLCM texture parameters, a window size of 5 by 5 pixels, and 32 number of grey levels were used as suggested in the literature (Mishra et al. 2019; Numbisi et al. 2019).
Sentinel-2
The S2 archive provided by ESA was used in combination with S1. Five bands were used: red (R), green (G), blue (B), near-infra-red (NIR) and red-edge (RE) at the spatial resolution of 10 m. The images were acquired using GEE, which uses the Sen2Cor module for the preprocessing of S2 images. Since the area is cloudy throughout the year, the cloud percentage per pixel was set to 5%, and for each band to get a useful image. The composite image (median image) was generated between 2017 and 2020. Seven vegetations indices (NDVI, GLI, EVI, SAVI, MSAVI, TCARI, VARI, see Table 2) were generated to provide additional information on the biophysical properties of the vegetation in the study area.
Data analysis
Random forest classification
Random Forest (RF) is a commonly used machine learning algorithm for classification, which combines the output of multiple decision trees to reach a single classification result. It could predict a feature class, or the probability of belonging to a class. RF reduces the risk of overfitting, provides flexibility (as it is not affected by data distribution or missing values) and gives information on the feature importance.
To classify the image features from S1 and S2, the data were split in train (75%) and test (25%) sets. A 10-folds cross validation with 10 repetitions was used to train the model using the train set, and the optimal variables were randomly sampled at each split. The Overall Accuracy (OA), the Producer and User Accuracies (PA and UA), and the area under the curve were generated as evaluation metrics for the classification (Abu et al. 2021). The trained model was used to predict AFS classes on the image, and to generate the probability map of each feature class. To reduce the salt and pepper effect on the map, a probability pass filter of 3 by 3 pixels was applied on the classified map. The spatial resolution was evaluated and integrated in the area analysis.
Spatial error assessment
The probability map of each feature class, generated from RF algorithm, was used to generate an entropy map using the Shannon entropy (Eq. 1). The entropy values range from 0 to 1, where high entropy values are associated with high probability of classification error (Roodposhti et al. 2019).
where H(x) is the entropy value for pixel (x), and Pi is the probability value of the pixel (x) for the AFS class i.
The pixels of the entropy map were grouped into two classes (error and good classification) using predefined entropy threshold’s value. This was referred to as error map. Different threshold values were evaluated: (1) a single entropy threshold value for the entire map (Roodposhti et al. 2019). Here four values were evaluated (0.2; 0.3, 0.4; 0.5). (2) Entropy threshold value corresponding to each feature class. To get the value for each class, field polygons were used to extract entropy pixel values for each class. Under normal distribution, the mean value was selected as threshold for the given class. The extracted values were cocoa = 0.32; palm = 0.52; farm = 0.3 and rubber = 0.43. The error maps were then used to remove error pixels from the classified map. Since the error map from (2) was based on field plots, it was used as reference with which other error maps were compared to evaluate under- and overestimation for each class.
Geographically weighted regression (GWR)
A GWR model (2) was implemented to evaluate non-stationarity on the error maps. Non-stationarity occurs when a global model such as ordinary least square model fails to capture the spatial relationship between variables (Narayan Mishra et al. 2021). GWR is described as a spatial and statistical technique for modelling heterogeneous processes when the relationship between the dependent and the independent variables varies as a function of spatial location on the map (Brunsdon et al. 1996).
where yi is the classification (error of good classification) at location i; βi0 is the intercept variable at location i; βik: represents the local regression coefficient for variable k at location i. and Xik the independent variable k at location i and εj represents the residual error at location i.
To implement GWR, 500 points were randomly distributed over the study area to extract pixel values from the independent variables (satellite data) and the dependent variable (error maps). The relevant features were selected based on the Akaike Information Criterion (AIC) in stepwise logistic regression, and the residuals were evaluated for spatial autocorrelation (Comber et al. 2020). No evidence of spatial autocorrelation would suggest a stationary map, therefore a GWR model is not applicable. However, if there is evidence of spatial autocorrelation, a Multiscale-GWR model (MS-GWR) would be applied to determine the spatial scale at which each predictor varied. If the residuals from the MS-GWR model are spatially autocorrelated, then a specific variant of GWR (MS-GWR or Mixed-GWR) will be applied to calculate the coefficient of the variable across the map (Comber et al. 2020). This analysis was done in R using the packages Raster, GWmodel and ggplot2.
Results
Image classification
Texture parameters and vegetation indices generated from S1 and S2 data, respectively, were used to train a RF model for the classification of four AFS in the region. The classification suggested a high performance of OA = 0.94 (Kappa = 0.92), with the smallest producer’s accuracy for cocoa (PA = 0.88 and UA = 0.91). The vegetation over the protected area was classified mainly as cocoa and rubber plantations (Fig. 2). When looking at the field plots, the classification showed some confusion between features classes. In Fig. 1a, rubber and farm pixels were falsely classified as cocoa. Moreover, pixels corresponding to cocoa are falsely classified as palm or rubber (Fig. 1c, d respectively). As suggested by the AUC, cocoa and rubber plantations were more difficult to distinguish (AUC = 0.95) compared to farm and palm plantation (AUC = 0.98 and 0.99 respectively).

Classification of agroforestry systems in the south of Côte d’Ivoire. Zoom on the field plots is presented in the right and left side of the classification. White dots on the image represented the areas that have been masked out
Spatial error assessment
To model the spatial distribution of the error, an entropy map was generated based on the probability of each feature class, where different thresholds were used to produce the error maps (Fig. 3). The figure indicated that higher entropy threshold values (thr = 0.5 for example) resulted in smaller area of the classification error (38.5% compared to 58.3% for thr = 0.2), which could result in underestimation of the classification error for larger threshold values or overestimation for smaller values. For each threshold, the protected areas were labelled as error, with some points corresponding to an AFS within their boundary. The area of each AFS at different thresholds was evaluated against the reference, which showed that there was an overestimation of the error with thr = 0.2 and thr = 0.3, corresponding to ca. 1 865.5 km2 and 645.3 km2, respectively. In addition, thr = 0.4 and thr = 0.5 showed an underestimation of the error (376.3 km2 and 1 141.5 km2, respectively). The difference in the cocoa area (134.5 km2) between the error map with thr = 0.3 and the reference error map (based on field plots) was small compared to the other classes.

Error maps for different entropy thresholds of agroforestry systems in south Côte d’Ivoire
The spatial distribution of the classification error (reference error map) was used to remove erroneous pixels from the classified AFS map (Fig. 4). The result showed that the method was efficient to deal with the classification error as illustrated by Fig. 4c. However, removal of the erroneous pixels also partly removed classified pixels (Fig. 4d). The area statistics indicated that 72.8% (7 425 ha) of the area is allocated to cocoa plantation, 15.3% to rubber (1 555 ha), 7.9% to agriculture (804 ha) and 4.09% for to palm (417 ha). Based on the results, there was evidence of encroachment in the protected areas, where the detected feature classes included cocoa (8.1%: 197 ha), rubber (8.1%: 16 ha) and farm (1 ha).

Improved classification of agroforestry systems in southern Côte d’Ivoire using entropy value threshold derived from field plot
Geographically weighted regression (GWR)
The stepwise regression indicated that 12 features were significant to model the distribution of the classification error across the map (R2 = 0.78). The residual analysis of the regression showed that there was no evidence of spatial autocorrelation (p = 0.66). However, there was evidence of spatial autocorrelation in the scenario with the overestimated error (thr = 0.2), as indicated in Table 3.
Discussion
Cocoa farms are established in small scale plantations, which resulted in a salt and pepper effects that are difficult to interpret. Therefore, a smooth filter was used to correct this effect. The analysis detected 88% of the cocoa in the region, of which 91% were accurately classified. This performance was superior to a comparable study in Côte d’Ivoire (PA = 82.9 and UA = 62.2) carried out by Abu et al. (2021). This could be explained by the size of the study area: Abu et al. (2021) worked on the entire country level, whereas our study area was limited to the cocoa production zone. In central Africa, an accuracy of 89.76% was obtained in Cameroon (Numbisi et al. 2019). This study used higher resolution images to delineate cocoa agroforestry from secondary forest. In Côte d’Ivoire, cocoa plantations are established as full sun (with few to no forest trees), thus their structure looks like rubber plantations, whereas in Cameroon, cocoa is grown under trees and are infeasible to be separated from secondary forest. This difference in context justifies the difference in methodology and in the results. An accuracy of 97.6% was obtained for the classification of a cocoa plantation in Brazil using S1 & S2 and deep learning (Filella 2018). The study reported a high level of prediction error in the final map, leading to the conclusion that the spatial and spectral resolutions of S2 is inappropriate to map cocoa agroforests. In fact, classifying cocoa agroforests requires high resolution imagery, which is not the case for full sun cocoa, for which S1 and S2 have been successfully used (Abu et al. 2021).
To reduce the error in the classification, Shannon entropy was added to the classification workflow to model the classification error. Here, entropy refers to the likelihood of a pixel to be a particular feature class. It is used in classification workflow as a weighted uncertainty metric to compare different classification models, or to compute the uncertainty of classification at pixel level (Numbisi et al. 2019; Roodposhti et al. 2019). A threshold value of 0.4 was used by Numbissi et al. (2019) for the classification of cocoa agroforestry in central Africa, where optimal threshold value was found between 0.3 and 0.4 with 0.4 slightly underestimating the map error. Roodposhti et al. (2019) found that the optimal threshold value was 0.2 for homogenous farming landscapes like corn, grass, and soybean. Thus, depending on final use of the map, a threshold of 0.3 or 0.4 could be used. The value at 0.3 would be a rigorous choice to limit probability of false detection for monitoring cocoa extension around protected areas. The spectral confusion between cocoa, rubber, palm, and forest was used to detect encroachment. Consequently, high entropy values were associated with pixels in the protected areas, so that only footprints of encroachment could be detected.
The expansion of cocoa plantation is acknowledged as the main driver of deforestation in Côte d’Ivoire, and evidence of encroachment in protected areas has been reported (Abu et al. 2021). We detected encroachment of cocoa in the Taï National Park. The distribution of the plantations within the park were located around the limit of the study area with a pattern that was like artefacts. This could be because a composite image was used as input layer since the use of single layers was infeasible due to presence of clouds in the region throughout the year. Therefore, validation would only be possible via fieldwork, interpretation of aerial photography or UAV data. Evaluation of the spatial autocorrelation on the image was necessary to identify local drivers of the error on the map. The study reported that the spatial distribution of the classification error was not related to any local condition. However, signs of local conditions associated with errors revealed when the error was highly overestimated (thr = 0.2).
The proposed methodology provides a framework for more reliable and accurate classification, particularly for AFS established within complex landscapes. It shows a pathway to model the spatial distribution of the classification error on the map and improve the classification by showing pixels which are accurately classified. This is necessary for the monitoring of cocoa expansion around protected areas to limit the risk of false detection. In addition, an accurate map is required to deliver accurate estimation of carbon stocks in each landscape for carbon estimation studies.
Conclusion
This study aimed at modelling the spatial distribution of the classification error in cocoa AFS in Côte d’Ivoire. The proposed model integrates the Shannon entropy in the classification framework to capture the classification error on the map. It was found that the entropy threshold value should be selected between 0.3 and 0.4 for the classification of full sun cocoa or cocoa agroforestry, respectively. Additionally, the model was able to detect encroachment in protected areas and could be used for monitoring the expansion of cocoa. This proposed methodology could also be used for image classification in presence of classes that are difficult to be separated. S1 and S2 could be used to the near-real time monitoring of cocoa plantation in Côte d’Ivoire, and the classification on the map could be corrected using other techniques like spectral-spatial super resolution image reconstitution, in combination with advanced classification approaches like deep learning.
References
Abu I, Szantoi Z, Brink A, Robuchon M, Thiel M (2021) Detecting cocoa plantations in Côte d’Ivoire and Ghana and their implications on protected areas. Ecol Ind. https://doi.org/10.1016/J.ECOLIND.2021.107863
Aguilar R, Zurita-Milla R, Izquierdo-Verdiguier E, de By RA (2018) A cloud-based multi-temporal ensemble classifier to map smallholder farming systems. Remote Sens 10:5. https://doi.org/10.3390/rs10050729
Dean A (2019) Deforestation and Climate Change | Climate Council. Retrieved Sep 1 2021 from https://www.climatecouncil.org.au/deforestation/
Ashiagbor G, Forkuo EK, Asante WA, Acheampong E, Quaye-Ballard JA, Boamah P, Foli E (2020) Pixel-based and object-oriented approaches in segregating cocoa from forest in the Juabeso-Bia landscape of Ghana. Remote Sens Appl Soc Environ 19:100349. https://doi.org/10.1016/J.RSASE.2020.100349
Bitty AE, Gonedele SB, Koffi Bene JC, Kouass PQ, Mcgraw WS (2015) Tropical conservation science | ISSN 1940–0829 | Tropicalconservationscience.org Cite this paper as. Mongabay.Com Open Access J-Trop Conserv Sci 8(1), 95–113. http://creativecommons.org/licenses/by/3.0/us/.The:95-113.Availableonline:www.tropicalconservationscience.org
Boeckx P, Bauters M, Dewettinck K (2020) Poverty and climate change challenges for sustainable intensification of cocoa systems. Curr Opin Environ Sustain 47:106–111. https://doi.org/10.1016/J.COSUST.2020.10.012
Brunsdon C, Fotheringham AS, Charlton ME (1996) Geographically weighted regression: a method for exploring spatial nonstationarity. Geogr Anal 28(4):281–298. https://doi.org/10.1111/J.1538-4632.1996.TB00936.X
Busquet M, Bosma N, Hummels H (2021) A multidimensional perspective on child labor in the value chain: the case of the cocoa value chain in West Africa. World Dev 146:105601. https://doi.org/10.1016/J.WORLDDEV.2021.105601
Comber A, Brunsdon C, Charlton M, Dong G, Harris R, Lu B, Harris P (2020) The GWR route map: a guide to the informed application of Geographically Weighted Regression, 1–34. http://arxiv.org/abs/2004.06070
Copernicus (2022) User guides—Sentinel-1 SAR—acquisition modes—Sentinel Online—Sentinel Online. Accessed 3 June 2022 https://sentinels.copernicus.eu/web/sentinel/user-guides/sentinel-1-sar/acquisition-modes
Earth M (2021) (4) Mighty Earth ? (@StandMighty)/Twitter. Accessed 15 June 2022 https://twitter.com/StandMighty?ref_src=twsrc%5Etfw%7Ctwcamp%5Etweetembed%7Ctwterm%5E1362451252659986433%7Ctwgr%5E%7Ctwcon%5Es1_&ref_url=https%3A%2F%2Fwww.agenceecofin.com%2Fcacao%2F1902-85365-la-cote-d-ivoire-a-perdu-47-000-hectares-de-forets-au-profit-d
ECOWAS (2016) Import and export | Economic Community of West African States(ECOWAS). Accessed 31 August 2021 https://www.ecowas.int/doing-business-in-ecowas/import-and-export/
Filella GB (2018) Cocoa segmentation in Satellite images with deep learning. ETH Zurich, Zürich
GIZ (2020) Strengthening governance and sustainable management of natural resources in the Comoé and Taï regions. Accessed 1 September 2021 https://www.giz.de/en/worldwide/30013.html
GVR (2019) Cocoa Beans Market Size, Analysis | Global Industry Report, 2019–2025. Accessed 31 August 2021 https://www.grandviewresearch.com/industry-analysis/cocoa-beans-market
Hall-Beyer M (2017) GLCM texture: a tutorial v.3.0 March 2017. http://www.ucalgary.ca/UofC/nasdev/mhallbey/research.htm
ILO (2017) Global estimates of child labour: results and trends, 2012–2016 International Labour Office (ILO), Geneva, 2017 ISBN: 978–92–2–130152–3 (print) ISBN: 978–92–2–130153–0
International Anti-slavery (2004) The cocoa industry in West Africa: a history of exploitation. Thomas Clarkson House. https://doi.org/10.1038/164306b0
Mishra VN, Prasad R, Rai PK, Vishwakarma AK, Arora A (2019) Performance evaluation of textural features in improving land use/land cover classification accuracy of heterogeneous landscape using multi-sensor remote sensing data. Earth Sci Inf 12(1):71–86. https://doi.org/10.1007/S12145-018-0369-Z/TABLES/10
Narayan Mishra V, Kumar V, Prasad R, Punia M (2021) Geographically weighted method integrated with logistic regression for analyzing spatially varying accuracy measures of remote sensing image classification. J Indian Soc Remote Sens. https://doi.org/10.1007/s12524-020-01286-2
Numbisi FN, Van Coillie FMB, De Wulf R (2019) Delineation of cocoa agroforests using multiseason sentinel-1 SAR images: a low grey level range reduces uncertainties in GLCM texture-based mapping. ISPRS Int J Geo-Inf. https://doi.org/10.3390/ijgi8040179
ProLand U (2020) The role of governments in making certification effective: a synthesis of the evidence and a case study of cocoa in Côte d’Ivoire. Retrieved from www.tetratechintdev.com
Pye-Smith K, Toledano (2016) A brighter future for cocoa farmers: how the vision for change programme is raising productivity and improving rural livelihoods. ICRAF Trees for Change no. 13. Nairobi: World Agroforestry Centre
Rinkesh (2020) Various causes, effects and surprising solutions to soil degradation—conserve energy future. Accessed 1 September 2021 https://www.conserve-energy-future.com/causes-effects-solutions-soil-degradation.php
Roodposhti MS, Aryal J, Lucieer A, Bryan BA (2019) Uncertainty assessment of hyperspectral image classification: deep learning vs. random forest. Entropy 21(1):1–15. https://doi.org/10.3390/e21010078
Ruf F, Schroth G, Doffangui K (2014) Climate change, cocoa migrations and deforestation in West Africa: what does the past tell us about the future? Sustain Sci 10(1):101–111. https://doi.org/10.1007/S11625-014-0282-4
Sabas BYS, Danmo KG, Madeleine KAT, Jan B (2020) Cocoa production and forest dynamics in ivory coast from 1985 to 2019. Land 9(12):524. https://doi.org/10.3390/LAND9120524
Shahbandeh M (2021) Cocoa production by country 2019/2020 | Statista. Accessed 28 May 2021 https://www.statista.com/statistics/263855/cocoa-bean-production-worldwide-by-region/
Yao B, Sabas S, Danmo KG, Akoua K, Madeleine T, Jan B, Ci KATM (2020) Cocoa production and forest dynamics in ivory coast from 1985 to 2019. Land. https://doi.org/10.3390/land9120524
Acknowledgements
Authors acknowledge the support from the German Federal Ministry for Education and Research (BMBF) via the project carrier at the German Aerospace Center (DLR Projektträger) through the research project: WASCAL-DE-Coop (FKZ: 01LG1808A).
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Kanmegne Tamga, D., Latifi, H., Ullmann, T. et al. Modelling the spatial distribution of the classification error of remote sensing data in cocoa agroforestry systems. Agroforest Syst 97, 109–119 (2023). https://doi.org/10.1007/s10457-022-00791-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10457-022-00791-2