
Real knowledge is to know the extent of one’s ignorance.
Confucius.
Abstract
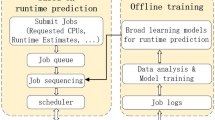
The performance of scheduling algorithms for HPC jobs highly depends on the accuracy of job runtime values. Prior research has established that neither user-provided runtimes nor system-generated runtime predictions are accurate. We propose a new scheduling platform that performs well in spite of runtime uncertainties. The key observation that we use for building our platform is the fact that two important classes of scheduling strategies (backfilling and plan based) differ in terms of sensitivity to runtime accuracy. We first confirm this observation by performing trace-based simulations to characterize the sensitivity of different scheduling strategies to job runtime accuracy. We then apply gradient boosting tree regression as a meta-learning approach to estimate the reliability of the system-generated job runtimes. The estimated prediction reliability of job runtimes is then used to choose a specific class of scheduling algorithm. Our hybrid scheduling platform uses a plan-based scheduling strategy for jobs with high expected runtime accuracy and backfills the remaining jobs on top of the planned jobs. While resource sharing is used to minimize fragmentation of resources, a specific ratio of CPU cores is reserved for backfilling of less predictable jobs to avoid starvation of these jobs. This ratio is adapted dynamically based on the resource requirement ratio of predictable jobs among recently submitted jobs. We perform extensive trace-driven simulations on real-world production traces to show that our hybrid scheduling platform outperforms both pure backfilling and pure plan-based scheduling algorithms.













Similar content being viewed by others


References
Lee CB, Schwartzman Y, Hardy J, Snavely A (2004) Are user runtime estimates inherently inaccurate? In: Workshop on Job Scheduling Strategies for Parallel Processing. Springer, pp 253–263
Tang W, Lan Z, Desai N, Buettner D (2009) Fault-aware, utility-based job scheduling on blue, gene/p systems. In: 2009 IEEE International Conference on Cluster Computing and Workshops. IEEE, pp 1–10
Fan Y, Rich P, Allcock WE, Papka ME, Lan Z (2017) Trade-off between prediction accuracy and underestimation rate in job runtime estimates. In: 2017 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, pp 530–540
Tchernykh A, Schwiegelsohn U, Alexandrov V, Talbi E-G (2015) Towards understanding uncertainty in cloud computing resource provisioning. Procedia Comput Sci 51:1772–1781
Zheng X, Zhou Z, Yang X, Lan Z, Wang J (2016) Exploring plan-based scheduling for large-scale computing systems. In: 2016 IEEE International Conference on Cluster Computing (CLUSTER). IEEE, pp 259–268
Bosnić Z, Kononenko I (2008) Estimation of individual prediction reliability using the local sensitivity analysis. Appl Intell 29(3):187–203
Hovestadt M, Kao O, Keller A, Streit A (2003) Scheduling in HPC resource management systems: queuing vs. planning. In: Workshop on Job Scheduling Strategies for Parallel Processing. Springer, pp 1–20
Srinivasan S, Kettimuthu R, Subramani V, Sadayappan P (2002) Characterization of backfilling strategies for parallel job scheduling. In: International Conference on Parallel Processing Workshops, 2002. Proceedings. IEEE, pp 514–519
Skovira J, Chan W, Zhou H, Lifka D (1996) The easy loadleveler API project. In: Workshop on Job Scheduling Strategies for Parallel Processing. Springer, pp 41–47
Talby D, Feitelson DG (1999) Supporting priorities and improving utilization of the IBM SP scheduler using slack-based backfilling. In: 13th International and 10th Symposium on Parallel and Distributed Processing Parallel Processing, 1999. 1999 IPPS/SPDP. Proceedings. IEEE, pp 513–517
Yoo AB, Jette MA, Grondona M (2003) Slurm: simple linux utility for resource management. In: Workshop on Job Scheduling Strategies for Parallel Processing. Springer, pp 44–60
Desai N (2005) Cobalt: an open source platform for HPC system software research. In: Edinburgh BG/L System Software Workshop, pp 803–820
Tsafrir D, Etsion Y, Feitelson DG (2007) Backfilling using system-generated predictions rather than user runtime estimates. IEEE Trans Parallel Distrib Syst 18(6):789–803
Xhafa F, Carretero J, Dorronsoro B, Alba E (2012) A tabu search algorithm for scheduling independent jobs in computational grids. Comput Inform 28(2):237–250
Klusáček D, Chlumskỳ V, Rudová H (2015) Planning and optimization in torque resource manager. In: Proceedings of the 24th International Symposium on High-Performance Parallel and Distributed Computing. ACM, pp 203–206
Im S, Naghshnejad M, Singhal M (2016) Scheduling jobs with non-uniform demands on multiple servers without interruption. In: IEEE INFOCOM 2016—The 35th Annual IEEE International Conference on Computer Communications, April, pp 1–9
Parallel workloads archive. http://cs.huji.ac.il/labs/parallel/workloads. Accessed 2015-07-01
Sonmez O, Yigitbasi N, Iosup A, Epema D (2009) Trace-based evaluation of job runtime and queue wait time predictions in grids. In: Proceedings of the 18th ACM International Symposium on High Performance Distributed Computing. ACM, pp 111–120
Gaussier E, Glesser D, Reis V, Trystram D (2015) Improving backfilling by using machine learning to predict running times. In: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. ACM, p 64
Bhimani J, Mi N, Leeser M, Yang Z (2017) Fim: performance prediction for parallel computation in iterative data processing applications. In: 2017 IEEE 10th International Conference on Cloud Computing (CLOUD). IEEE, pp 359–366
Obaida MA, Liu J, Chennupati G, Santhi N, Eidenbenz S (2018) Parallel application performance prediction using analysis based models and HPC simulations. In: Proceedings of the 2018 ACM SIGSIM Conference on Principles of Advanced Discrete Simulation. ACM, pp 49–59
Naghshnejad M, Singhal M (2018) Adaptive online runtime prediction to improve HPC applications latency in cloud. In: 2018 IEEE 11th International Conference on Cloud Computing (CLOUD). IEEE, pp 762–769
Lakshminarayanan B, Pritzel A, Blundell C (2017) Simple and scalable predictive uncertainty estimation using deep ensembles. In: Advances in Neural Information Processing Systems, pp 6402–6413
Gibbons R (1997) A historical application profiler for use by parallel schedulers. In: Workshop on Job Scheduling Strategies for Parallel Processing. Springer, pp 58–77
Tang W, Desai N, Buettner D, Lan Z (2010) Analyzing and adjusting user runtime estimates to improve job scheduling on the blue gene/p. In: 2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS). IEEE, pp 1–11
Smith W, Foster I, Taylor V (1998) Predicting application run times using historical information. In: Feitelson D G, Rudolph L (eds) Job scheduling strategies for parallel processing. Springer, Berlin, pp 122–142
Wyatt II MR, Herbein S, Gamblin T, Moody A, Ahn DH, Taufer M (2018) PRIONN: predicting runtime and IO using neural networks. In: Proceedings of the 47th International Conference on Parallel Processing. ACM, p 46
Nissimov A, Feitelson DG (2007) Probabilistic backfilling. In: Workshop on Job Scheduling Strategies for Parallel Processing. Springer, pp 102–115
Mendes CL, Reed DA (1998) Integrated compilation and scalability analysis for parallel systems. In: Proceedings. 1998 International Conference on Parallel Architectures and Compilation Techniques, 1998. IEEE, pp 385–392
Schopf JM, Berman F (1999) Using stochastic intervals to predict application behavior on contended resources. In: Proceedings. Fourth International Symposium on Parallel Architectures, Algorithms, and Networks, 1999 (I-SPAN’99). IEEE, pp 344–349
Matsunaga A, Fortes JA (2010) On the use of machine learning to predict the time and resources consumed by applications. In: Proceedings of the 2010 10th IEEE/ACM International Conference on Cluster, Cloud and Grid Computing. IEEE Computer Society, pp 495–504
Dimitriadou S, Karatza H (2010) Job scheduling in a distributed system using backfilling with inaccurate runtime computations. In: 2010 International Conference on Complex, Intelligent and Software Intensive Systems (CISIS). IEEE, pp 329–336
Ramírez-Velarde R, Tchernykh A, Barba-Jimenez C, Hirales-Carbajal A, Nolazco-Flores J (2017) Adaptive resource allocation with job runtime uncertainty. J Grid Comput 15(4):415–434
Ilyushkin A, Epema D (2018) The impact of task runtime estimate accuracy on scheduling workloads of workflows. In: 2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID). IEEE, pp 331–341
Hazan E et al (2016) Introduction to online convex optimization. Found Trends Optim 2(3–4):157–325
Ross S, Mineiro P, Langford J (2013) Normalized online learning. arXiv:1305.6646
Vanschoren J (2019) Meta-learning. In: Hutter F, Kotthoff L, Vanschoren J (eds) Automated machine learning: methods, systems, challenges. Springer, Cham, pp 35–61. https://doi.org/10.1007/978-3-030-05318-5_2
Friedman JH (2001) Greedy function approximation: a gradient boosting machine. Ann Stat 29(5):1189–1232
Chen T, Guestrin C (2016) Xgboost: a scalable tree boosting system. In: Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, pp 785–794
Friedman JH (2002) Stochastic gradient boosting. Comput Stat Data Anal 38(4):367–378
Hastie T, Tibshirani R, Friedman JH (2009) The elements of statistical learning: data mining, inference, and prediction, 2nd edn. Springer series in statistics. Springer, Berlin
Bosnić Z, Kononenko I (2008) Comparison of approaches for estimating reliability of individual regression predictions. Data Knowl Eng 67(3):504–516
Amvrosiadis G, Park JW, Ganger GR, Gibson GA, Baseman E, DeBardeleben N (2018) On the diversity of cluster workloads and its impact on research results. In: 2018 USENIX Annual Technical Conference (USENIX ATC 18), pp 533–546
Feitelson DG (2015) From repeatability to reproducibility and corroboration. ACM SIGOPS Oper Syst Rev 49(1):3–11
Mann ZÁ (2015) Allocation of virtual machines in cloud data centersa survey of problem models and optimization algorithms. ACM Comput Surv: CSUR 48(1):11
Pinedo ML (2012) Scheduling: theory, algorithms, and systems. Springer, Berlin
Augonnet C, Thibault S, Namyst R, Wacrenier P-A (2011) Starpu: a unified platform for task scheduling on heterogeneous multicore architectures. Concurr Comput Pract Exp 23(2):187–198
Witt C, Bux M, Gusew W, Leser U (2019) Predictive performance modeling for distributed batch processing using black box monitoring and machine learning. Inf Syst
Klusáček D, Rudová H (2010) Alea 2: job scheduling simulator. In: Proceedings of the 3rd International ICST Conference on Simulation Tools and Techniques. ICST (Institute for Computer Sciences, Social-Informatics and Telecommunications Engineering), p 61
Buyya R, Murshed M (2002) Gridsim: a toolkit for the modeling and simulation of distributed resource management and scheduling for grid computing. Concurr Comput Pract Exp 14(13–15):1175–1220
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Naghshnejad, M., Singhal, M. A hybrid scheduling platform: a runtime prediction reliability aware scheduling platform to improve HPC scheduling performance. J Supercomput 76, 122–149 (2020). https://doi.org/10.1007/s11227-019-03004-3
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-019-03004-3